Prepare Point Cloud Training Data
Steps
1.Data Preparation: The data format supported by this function is different from that supported by LiDAR360MLS and this function only supports data in LiData (*.LiData) format. Specific requirements are as follows:
- Training Data: Data with class labels. If there is no available labelled data, you can use the point cloud classification function of LiDAR360MLS to manually/automatically classify the point cloud data. For the methods of point cloud manual/automatic classification, refer to Point Cloud Full Supervised Labeling and Weak Supervised Labeling Process. In theory, the more labelled data involved in training, the better the quality of the trained model. We recommend using data with a range of at least 100m*100m for training to achieve good results. If multiple data are used for training, make sure that the categories of classification in each data are consistent. If not, it will have a negative impact on the quality of model training.
- Validation Data: Data with class labels. This data will be used as the "standard answer" for point cloud classification and used to calculate accuracy metrics such as the accuracy of the model classification. The classes of this data should be consistent with the training data.
2.Data Preprocessing
1)Firstly, click on the Prepare Training Data ![]() button in the classification tool, and use the Add function in Training Point Cloud and Validation Point Cloud to add corresponding data. This also includes Delete and Clear functions, which can delete specific files in the list and clear the file selection list.
button in the classification tool, and use the Add function in Training Point Cloud and Validation Point Cloud to add corresponding data. This also includes Delete and Clear functions, which can delete specific files in the list and clear the file selection list.
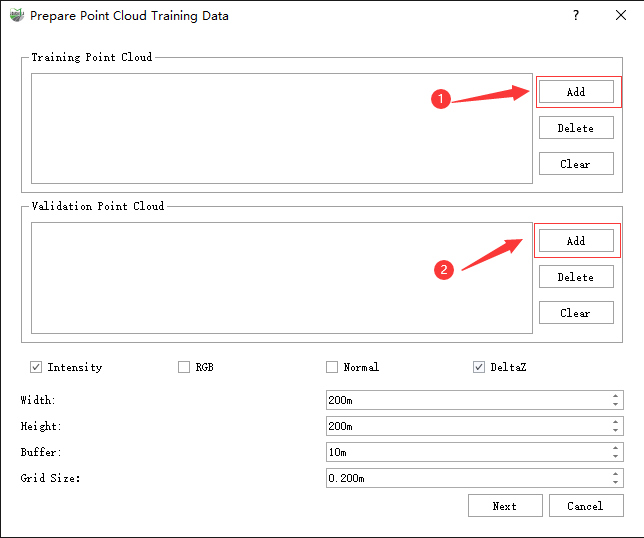
2)Select the feature information contained in the processed point cloud data. This function supports the following four features.
- Intensity: The intensity feature of the point cloud.
- RGB: Color feature.
- Normal Vector: The normal vector feature of the point cloud.
- Relative Elevation: Elevation feature relative to the ground.
Note: >It is recommended to keep RGB, Relative Elevation, and Intensity features. If there are no Intensity and RGB features in the data, the corresponding options cannot be selected. Even if the original data does not have Vector and Relative Elevation, they will be automatically generated later.
3)Select Slice Size
- Width and Height: Indicate the width and height of the point cloud data after slicing. The larger these two values are, the larger the amount of slice data and the slower the file reading speed. If the amount of slice data is too small, it results in not getting enough data for each training, which affects the final accuracy. Setting an appropriate Width and Height can improve the file reading speed during training.
- Buffer: The overlap length of the slice point cloud. Setting the overlap length can avoid the impact of the edge part of the point cloud on the training and validation results, which is generally set to 10 by default.
- Voxel Size: The size of the voxel sampling grid. The larger this value is, the sparser the point cloud used in training. Too sparse will affect the final accuracy. The smaller this value is, the denser the point cloud used in training and the computation increases. For data of indoor scenes, it is generally set to 0.02-0.04m by default, and for data of outdoor scenes, it is generally set to 0.05-0.2m by default.
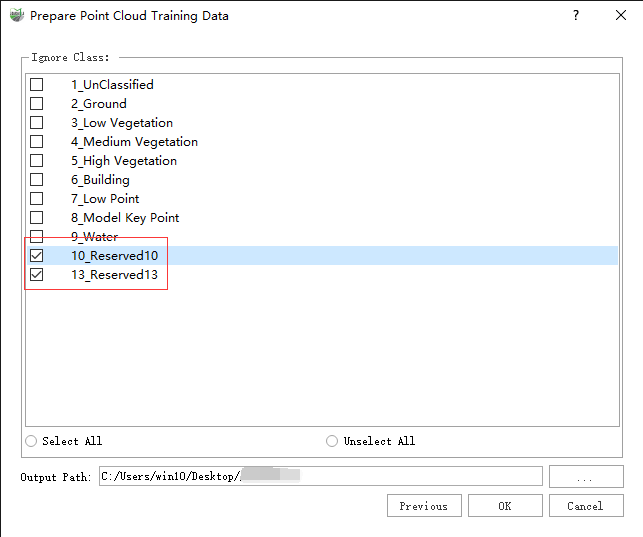
4)Click Next Page, and the Ignore Categories box that pops up shows the category information in the selected data. Here, you can select the classes to be ignored and map them to class 0 so that ignore this class in the subsequent training steps. Only the classes that need to be classified should be retained, and the unrelated classes should be selected and ignored. At Output Path, you can choose the data output folder, which is saved in the same directory as the current project by default. After clicking OK, the software starts processing data and users can view the data processing progress at the progress bar at the bottom of the software.
Note:
When using the WS-PCSS method, there must be Never Classified, or UnClassified categories. For specific explanations, refer to Point Cloud Full Supervised Labeling and Weak Supervised Labeling Process.
If there are "Never Classified" and "UnClassified" categories at the same time, the two categories will be automatically mapped to category 0 during the data preparation stage, and then participate in training.