Point Cloud Fully Supervised Labeling And Weakly Supervised Labeling Process
Concepts
1.Fully Supervised Training: Fully supervised training refers to the use of point cloud data with complete labeled information during the training process. Each point in the point cloud data needs to have a specific class label.
2.Weakly Supervised Training: Weakly supervised training refers to the training process where only partial labeled information is available. In the context of this module, weakly supervised learning means that only a small portion of the points have explicit class labels, while the remaining points are uniformly classified as uncategorized. For example, for a tree, only a part of the points need to be classified as a tree, while the rest can be classified as uncategorized.
Steps
1.Classification Processing:
Classification using the Classification Module: Refer to the Manual Editing Classification documentation;
Classification using the Profile Module: Refer to the Manual Classification in Profile documentation;
2.Fully Supervised Data Labeling: When training point cloud data by PCSS,LCP-PCSS and SPV-PCSS, data with full labelling is required. Point cloud data can be labeled using the built-in classification feature of LiDAR360MLS software (refer to Step 1).
(1)Principles for Labeling:
1)Each point of each object must be labeled.
2)Carefully select points when dealing with boundaries. If points from other objects are classified as the current object's category, it will have a significant impact on training.
3)Only label the classes of interest. For example, if you want to classify trees and buildings in point clouds during inference, you only need to label trees and buildings, while leaving the rest of the points uncategorized.
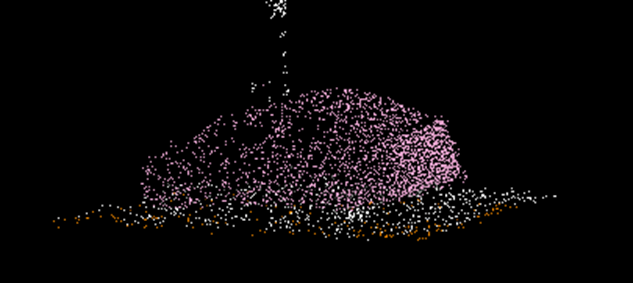
(2)The labeled point cloud should have the interested objects labeled with their respective classes, while the remaining points should be labeled as uncategorized, as shown in the example below.

3.Weakly Supervised (WS-PCSS) Data Labeling:
When using the WS-PCSS algorithm for training, you can use point cloud data with weak labels, which greatly reduces the labelling workload and improves production efficiency. The following describes the labeling method for weakly supervised learning;
Point cloud data can be labelled by using the built-in classification function of LiDAR360MLS software, following the same labelling process as described in step 1 and 2. However, fully labelling is not required for weakly supervised learning. Only partial points need to be labelled with their respective labels. The following principles should be followed when labelling:
1)Detailed subdivision of the object is not necessary during labelling. Only a portion of the points for each object needs to be labelled. For example, in the image below, difficult-to-label area can be left unlabeled, and only the target parts need to be labelled.

2)The labelled points should be evenly and uniformly distributed in the target object. For example, in the image below, the labelled points should cover all the characteristic parts of the object as far as possible.

3)You can label less point cloud, but mislabelling or over-labelling should be avoided.

Mislabelled

Correctly labelled
4)Each object in the scene should have labelled points as much as possible. As shown in the image below, every object in the scene should have labeled points, even if only 1% of the points are labelled.

5)When two objects are adjacent (or have overlapping area), both objects should have some labelled points. In the example below, both the ground and the car should have some labelled points because they are adjacent at the boundary.
6)The class with the smallest label index in the labelled data will be ignored during training. Therefore, at least one of Created Points, Unclassified, or Unclassified Points should be present in each LiData data.