Training Point Cloud Classification Model
Steps
1.Training process and parameter introduction
1)Firstly, click the Train Point Cloud Classification Model ![]() button.
button.
2)Click the button in the figure to select the training file generated in the previous step. You only need to select train.plyjson.
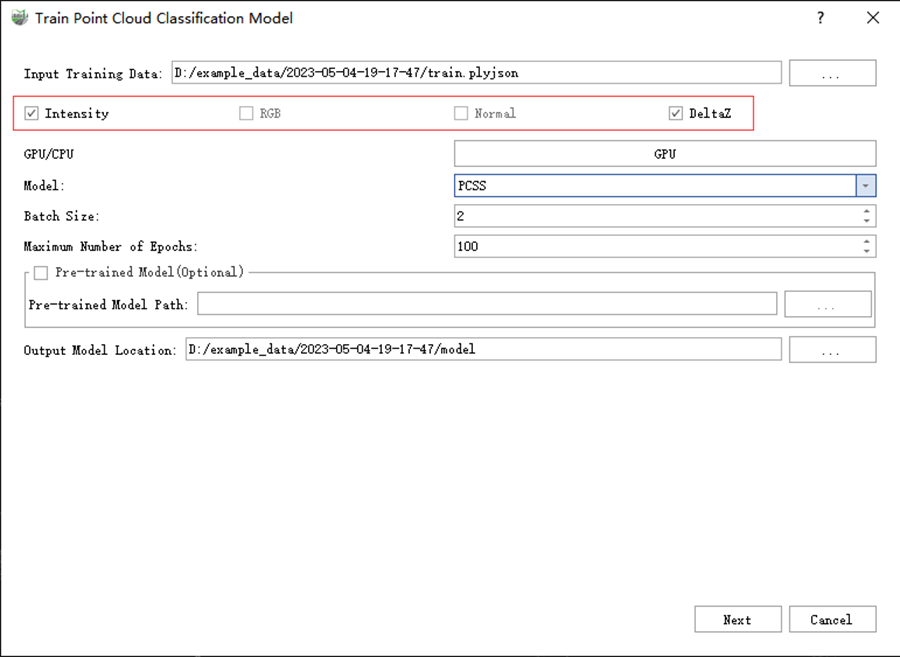
3)Select the features involved in the training. All features included in the data are checked by default. Features that are not checked during data preparation will be grayed out.
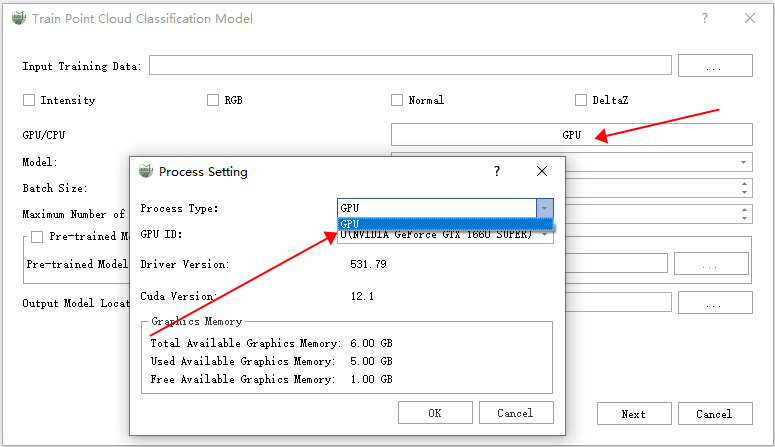
4)As shown in the figure, you can specify the GPU to be used for training in the drop-down menu, and this function only supports GPU for training.
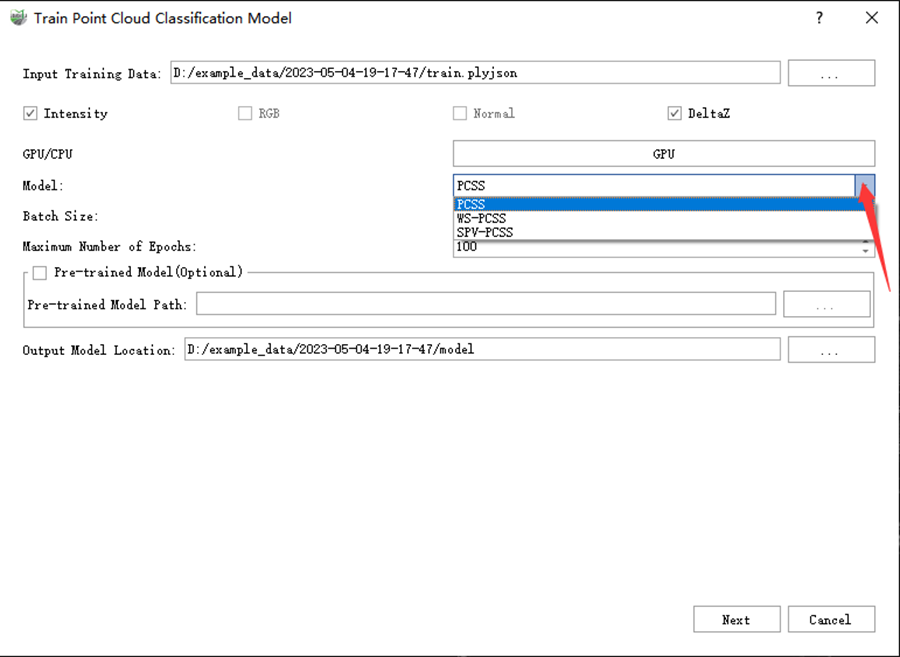
5)Training Model Selection: The software currently provides three deep learning method options. The characteristics of each algorithm are shown below. Users can choose according to specific needs.
- PCSS: A fully supervised point cloud semantic segmentation model with high accuracy. It is suitable for classification tasks that require high accuracy, but its speed is relatively slow. It requires fully labelled point cloud data and the training cycle is relatively long.
- SPV-PCSS: A fully supervised point cloud semantic segmentation model is suitable for classification tasks that focus on large-scale objects. The accuracy is relatively high and the inference speed is faster, but it requires fully labelled point cloud data and the training cycle is moderate.
- WS-PCSS: A weakly supervised point cloud semantic segmentation model, which can use less labelled point cloud data for training. Each point cloud data only needs to be labelled more than 1% of the labels, but the accuracy is lower than the fully supervised model. Its training and inference speed is slightly slower. However, this method can effectively reduce the workload of labelling.
- LCP-PCSS: A fully supervised point cloud semantic segmentation model, characterized by high accuracy and rapid training convergence, requires fewer iterations to train an effective classification model. This model is particularly suitable for classification tasks where high precision is essential. However, it necessitates the complete labeling of point cloud data.
6)Batch Size: This is the number of data inputs for each training session. For example, if the batch size is 2, then two groups of data are trained in the same batch. Theoretically, the larger the batch size, the higher the accuracy of the results obtained. It is recommended not to exceed 8. The upper limit is limited by the size of the video memory. According to different video memory sizes, the recommended batch size is as follows. When the memory or video memory is insufficient, you can appropriately reduce this parameter. In addition, it should be noted that the larger the ratio of data-labeled points to total points, the more video memory the WS-PCSS algorithm uses.
| PCSS | WS-PCSS(1%) | SPV-PCSS | LCP-PCSS | |
|---|---|---|---|---|
| 8GB | 2 | 1 | 2 | 4 |
| 10GB | 2 | 2 | 2 | 4 |
| 11GB | 2 | 2 | 2 | 4 |
| 12GB | 2 | 2 | 2 | 4 |
| 16GB | 4 | 2 | 4 | 8 |
| 24GB | 4 | 2 | 4 | 16 |
7)Maximum Epoch Number: The maximum training period. This parameter set needs to be adjusted according to the trend of loss and IoU. The specific numerical setting is best when the value of Loss no longer decreases and IoU no longer increases. The default is 100. Training is stopped when the average IoU does not improve in the validation set for 10 consecutive epochs.
8)Pre-trained Model: This is an optional feature. Its function is to select a pre-trained model, which can be used in two situations:
- If the training is unexpectedly interrupted, there is no need to retrain. You only need to use the model file saved at the time of interruption as a pre-trained model for training.
- When you already have a trained model and have new labelled data, you do not need to merge the original data and retrain. You only need to train based on the original model, which can effectively save time. However, the classes of the training data, the selected features, and the algorithm name need to remain consistent between the two training sessions.
9)Model Output Path: The output folder of the trained model. Saved in the project file by default.
10)After clicking Next, go to the training interface. The progress bar of the training process is displayed at the top of the interface and the training log is displayed in the box below.
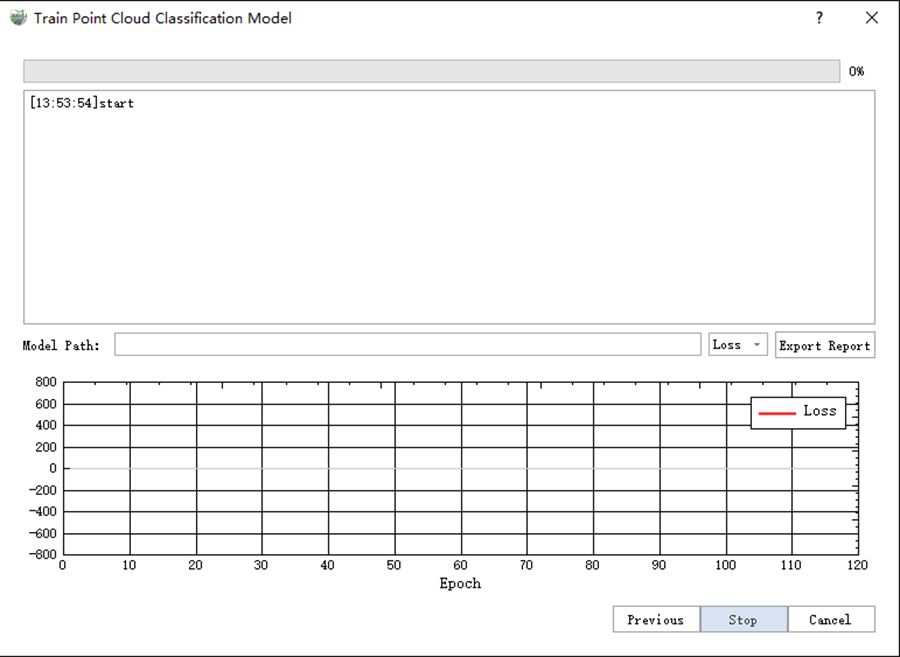
11)After clicking Start, the training begins. You can select the change curve you want to view from Loss, mIoU, and mAcc in the dropdown menu in the 1 place in the figure. After the training stops, you can click Export Report to print the training report. The report file is automatically saved in the project file. The trained model file is saved in the box marked 2 in the figure.
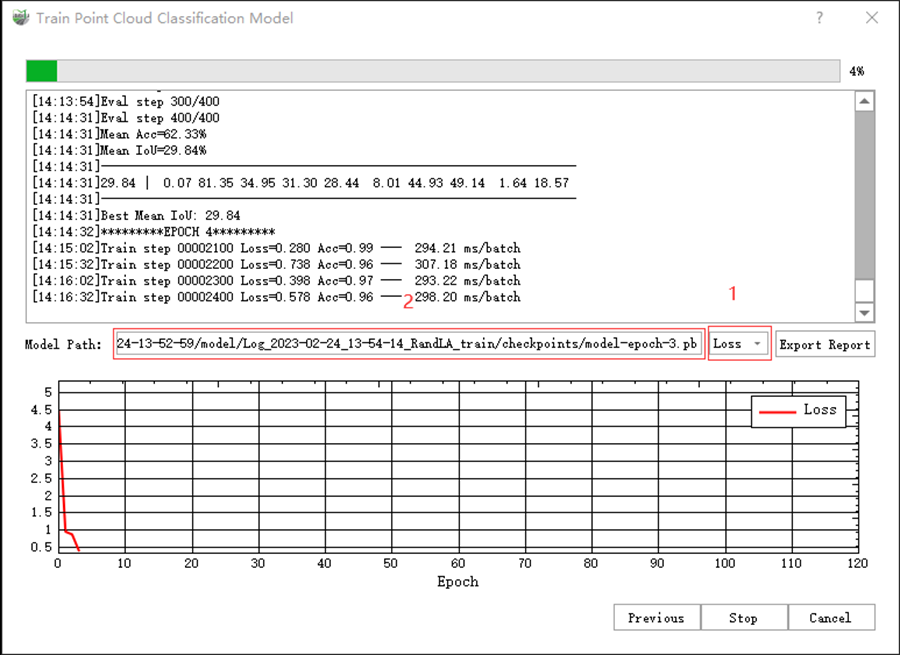
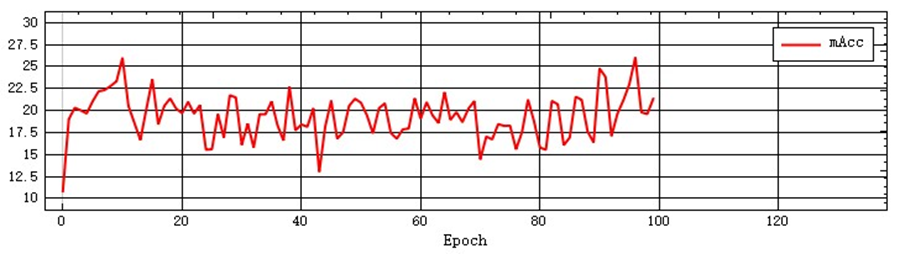
12)During the training process, you can observe the change in the curve to analyze the training effect.
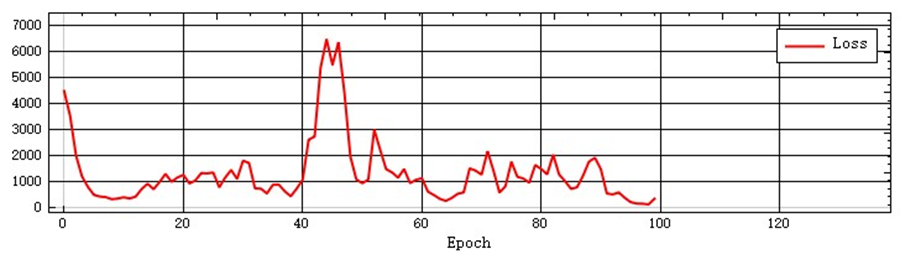
- Normally, Loss will decrease with the increase of Epoch and tend to stabilize after dozens or hundreds of Epochs. If this characteristic is not met or the Loss curve oscillates, it indicates that there is a problem with the training. Please stop the training, check the data and retrain.
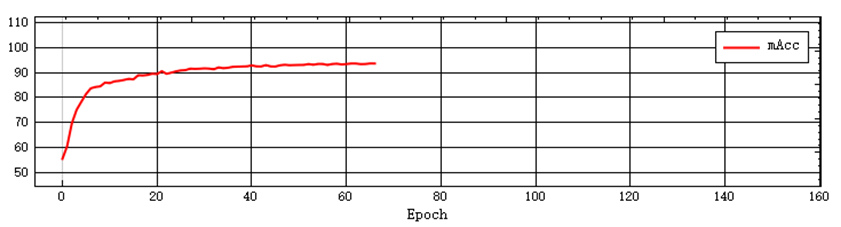
- Normally, the mAcc value will increase with the increase of Epoch and finally stabilize. If this characteristic is not met, it indicates that there is a problem with the training. Please stop the training, check the data and retrain.
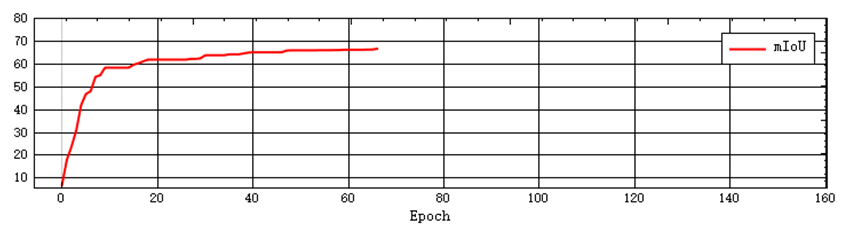
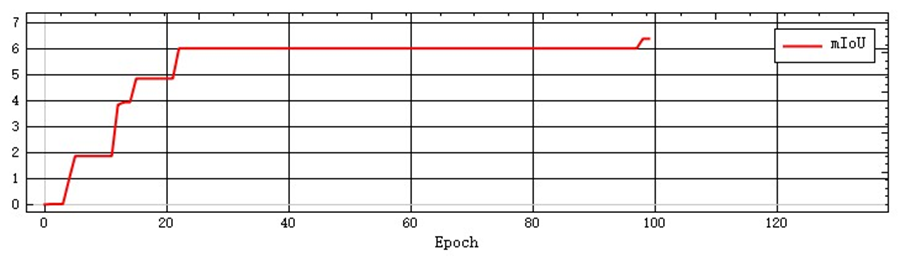
- Normally, mIoU will gradually increase and stabilize after a certain epoch. If mIoU does not stabilize in the end, it means that the model still has training potential. Please continue training using the load pre-trained model method until mIoU stabilizes. If mIoU does not increase, it indicates that there is a problem with the training. Please stop the training, check the data and retrain.
The figure below provides samples of the three curves for users to refer to.
Normal curves:
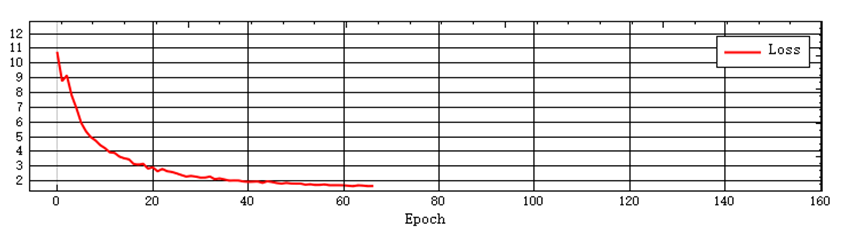
Examples of problematic curves:
2.Training Project File Structure:
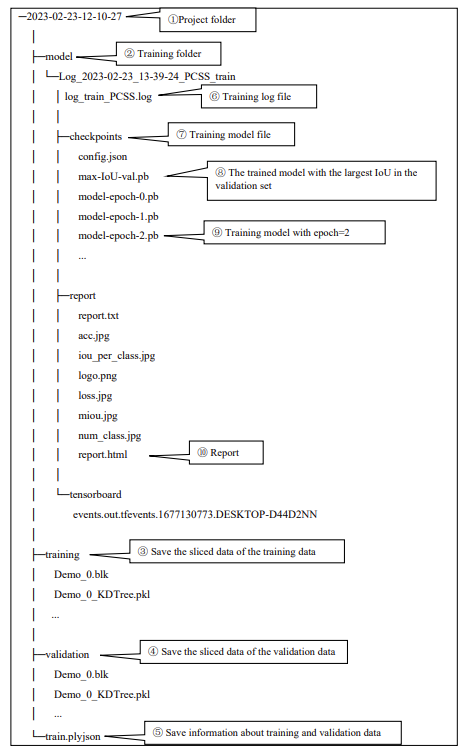
The table above shows an example of a project folder structure:
① 2023-02-23-12-10-27: Project folder is automatically generated in the data directory based on the processing time during the data processing stage.
② model: It stores the intermediate results of the training.
③ training: It stores the sliced data for training.
④ validation: It stores the sliced data for validation.
⑤ train.plyjson: It saves the relevant information of the training and validation data.
⑥ The Model folder stores the training result files. Multiple training results for the same dataset are saved in this folder. The example shows the training folder "Log_2023-02-23_13-39-24_PCSS_train". The log_train_PCSS.log file stores the training log data.
⑦ checkpoints folder: It stores the trained model files for this training.
⑧ max-IoU-val.pb: The trained model with the maximum validation IoU.
⑨ model-epoch-.pb: The trained models corresponding to each epoch.
Note: The model files for PCSS and WS-PCSS are in .pb format, while the model file for SPV-PCSS is in .pt format.
⑩ The report folder stores the files related to the report, including the report.html file in HTML format.
Note: The project folder mentioned here refers to the project folder of the training process.
3.Model Deployment: The trained models are saved in the model folder. You can copy this folder to another computer with an NVIDIA GPU and use LiDAR360MLS software for inference based on the trained model. Refer to the Classify Point Cloud Using Trained Model for the specific inference process. Please refer to the installation instructions in the module to check if your device supports the inference.