Classify Point Cloud Using Trained Model
Steps
1.Data Preparation: Before using the inference function, you need to prepare the following data:
Model: The model is trained using the custom deep learning classification feature. It can be found in the project directory -> model -> Log2023-02-14_10-15-29**_train(specific training directory) -> .pb/.pt. The model data is obtained after the training is complete.
Inference Data: The point cloud data that needs to be processed and unclassified, i.e., inference data, in the format of .LiData.
2.Inference
1)Click the Classify Point Cloud Using Trained Model![]() button, the setup interface pops up. Select the data to be classified in the Target Point Cloud box, which should be in.LiData format. This box has the same Add, Delete, and Clear functions as the training module. Click the Add button to add data to be classified.
button, the setup interface pops up. Select the data to be classified in the Target Point Cloud box, which should be in.LiData format. This box has the same Add, Delete, and Clear functions as the training module. Click the Add button to add data to be classified.
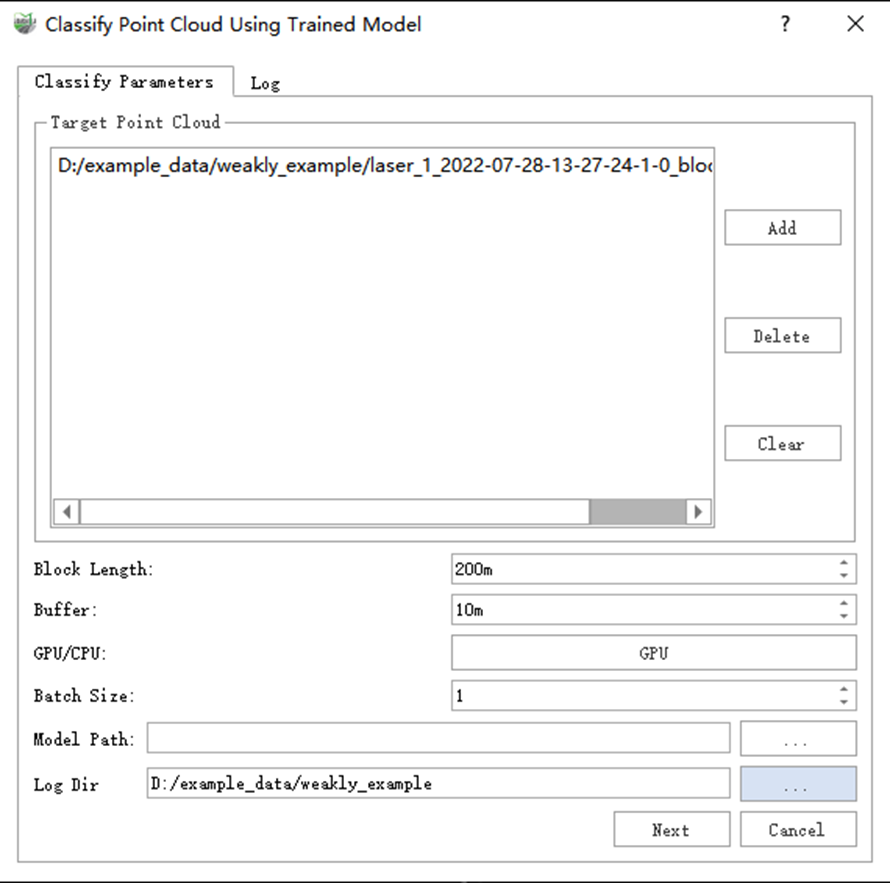
Chunk Length: The slice length of the data to be classified.
Buffer: The overlap length between adjacent slices during slicing. This is usually left at the default. These two values should be set consistently with the training.
GPU: Click the GPU button in the picture to select the GPU to be used for inference. Currently, only single GPU computing is supported.
Batch Size: The same as in training. The image below shows the recommended values.
PCSS WS-PCSS(1%) SPV-PCSS LCP-PCSS 8GB 4 1 4 4 10GB 6 1 4 4 11GB 6 1 6 6 12GB 8 1 8 8 16GB 8 2 8 8 24GB 8 2 8 16 Unclassified Threshold: Set the unclassified threshold here to distinguish unclassified points. It is usually set to 0.1 by default.
- Model Path: Select a model file that has been trained and is of high quality. If the user has no special needs, it is recommended to select max-IoU-val.pb/max-IoU-val.pt. If you are focusing on a specific category, it is recommended to select the file corresponding to the epoch with the highest IoU for that category based on the training report.
- Log Path: The storage path of the inference log. By default, it is stored in the project folder at the same level as the inference data.
2)Click Next to go to the inference interface. From top to bottom, there are a progress bar and a log window. Click Start to start inference. After the inference is finished, the selected.LiData file will be replaced.
Note:
During inference, the point cloud slice files and log files for the inference are automatically saved in the current project directory. For example, 2023-02-23-14-32-01_Inference and Log_2023-02-23_14-32-24_PCSS_inference save the point cloud slice files and the inference log files respectively.
The inference result automatically adds the classification information to the originally selected.LiData file. If there is category information, it will automatically be replaced.
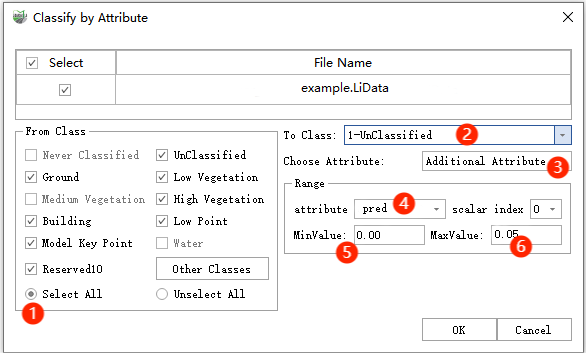
3.Extract unclassified points: If the target category classification effect in the inferred point cloud is the maximum, it should be the score. You can use Classification->Classification by Attribute to select the point cloud to be classified, and process it according to the pred additional attributes in order, as shown in the figure below. The pred attribute is generally set to 0 by default. It is recommended to set it to 0.1 as above, which can be adjusted according to the actual situation.