Support Vector Machine
Summary
This tool use Python Package scikit-learn and NumPy to build up the Random Forest model.
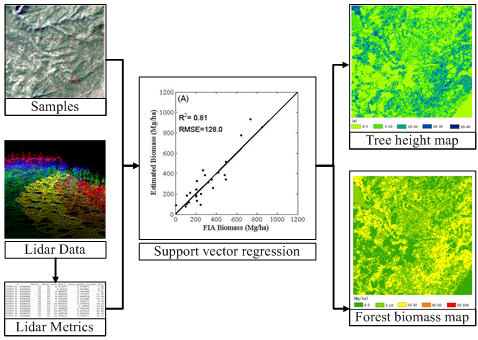
Usage
Navigate to ALS Forest > Regression Analysis > Support Vector Machine.
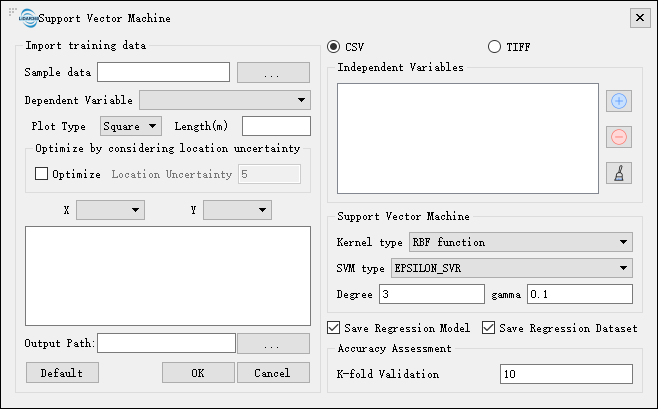
Settings
- Import Training Data: Refer to Sample Data and Independent Variables.
- Independent Variables: Refer to Sample Data and Independent Variables.
- Kernel Type: Users can select the type of kernel function here including RBF function, Linear, Polynomial, and Sigmoid.
- RBF Function (default):
 , where γ > 0.
, where γ > 0. - Linear:
 .
. - Polynomial:
 , where γ > 0.
, where γ > 0. - Sigmoid:
 .
.
- RBF Function (default):
- SVM Type: Two types of SVM method are provided.
- EPSILON_SVR (default): EPSILON SVR(ϵSVR ).
- NU_SVR: NU SVR(νSVR).
- Degree (default value is "3"): Kernel function parameter.
- Gamma (default value is "0.1"): Kernel function parameter.
- Accuracy Assessment: Based on the K-Fold cross validation model, a sample would be partitioned into k subsets according to input K-Fold value (no less than 2). Take one of subsets as a validation dataset and the remaining subsets as training datasets to form a model, then run this model and test the fitting of validation set to training sets. Repeat this process until every subset is treated as a validation set at least once and select out the model with the least MSE (mean square error) as the optimal model.
- Save Regression Model: Tick the checkbox to save the SVM model (Support Vector Machine.model) under the output path.
- Save Regression Dataset: Tick the checkbox to save the training dataset (Support Vector Machine.csv) in .csv format under the output path.
- Output Path: Choose an output directory. A support vector machine regression model report (Support Vector Machine.html), recording the model's parameters and accuracy (R-square, RMSE), would be generated under this directory. A prediction result file (Support Vector Machine.tif), based on the support vector machine regression model and input variables from a .tif or .csv file, would also be generated under this output directory.
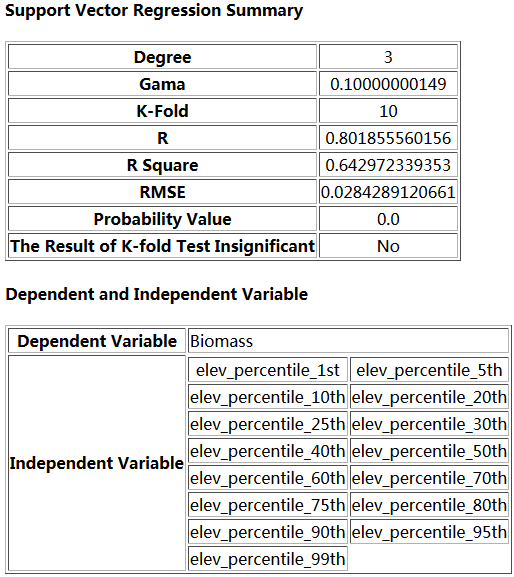
Note: The dimension of imported sample/training data must be within the scope of independent variables, which may be adjusted accordingly. The model/result is based on the passed-in variables.
@inproceedings{
author={Chang C C and Lin C J},
title={LIBSVM: A Library for Support Vector Machines},
booktitle={ACM,2(3):1-27},
year={2011}
}