Random Forest Regression
Description
This tool use Python Package scikit-learn and NumPy to build up the Random Forest model.
Usage
Click ALS Forest > Regression Analysis > Random Forest Regression.
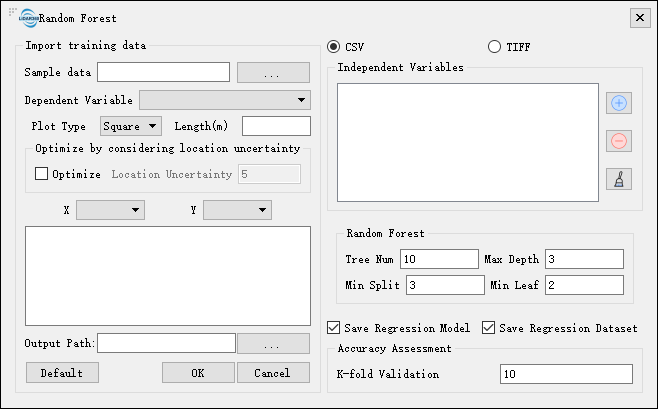
Parameters
- Sample Data: Please refer to Sample Data and Independent Variables。
- Independent Variables: Please refer to Sample Data and Independent Variables。
- Random Forest: These values define Random Forest's parameters.
- Tree Num:Tree number in the Random Forest model.
- Max Depth:The maximum depth of Random Forest model.
- Min Split:The minimum split of Random Forest model.
- Min Leaf:The minimum leaf number in Random Forest model.
- Accuracy Assessment:Use K-Fold cross-validation model. According to the inserted K-Fold parameters, divide the sample into K groups. Each group will be taken as testing data by training the model using other remianing samples. Note that K-Fold value should be larger than 1 (don't include 1).
- Save Regression Model: If the box is checked, a model named (Random Forest.model) will be generated in the output path, after the program being successfully run.
- Save Regression Dataset:If the box is checked, a training data model named (Random Forest.csv) will be generated in the output path, after the program being successfully run.
- Output Path: The path for the output files. The software will generate a model report (Random Forest.html) with the residuals and related values of the model, a result file (Random Forest.tif), and a regression model file (optional).
- Default Value: Restore all the default values for all parameters.
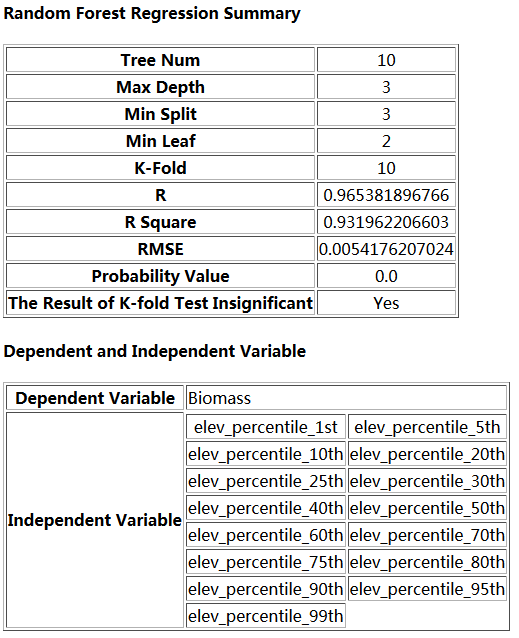
Note: The inserted sample data must be included in the range of inserted independent variables. The number of independent variables can be changed based on the users' situation. The final result is generated according to the inserted independent variables. Max Depth and Tree Num should be greater than 0.