Can LiDAR360 generate CHM in batches?
LiDAR360 can generate CHM in batches (ALS Forest > Batch Process > Canopy Height Model(CHM) Segmentation).
How to evaluate the accuracy of individual tree segmentation results?
For evaluation of individual tree segmentation accuracy, please refer to Li et al's article on (Li et al., 2012). By comparing with field measurement, the number of correctly segmented trees, the number of falsely segmented trees, and the number of missed trees are calculated according to the following formulae: recall (r), precision (p), and F-score (F). Recall indicates the tree detection rate, precision indicates the correctness of the detected trees, and F-score is the overall accuracy taking both commission and omission errors into consideration. The values of r, p and F vary from 0 to 1.



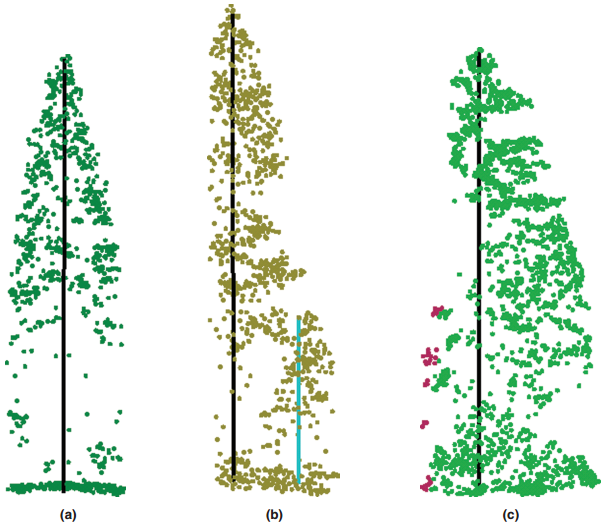
(a)Correctly detected tree (True Positive, TP)(b)undetected tree (False Negative, FN) (c)falsely detected tree(False Positive, FP)
What parameters affect the CHM segmentation accuracy and how should these parameters be set?
- The accuracy of CHM segmentation are affected by CHM resolution and Gaussian smoothing factor.
- CHM is the difference between DSM and DEM. The CHM resolution is determined by the resolution of DSM and DEM. Generally speaking, this value should not exceed one-third of the crown width, and the range can be set to 0.3-1m. Usually, the resolution of 0.5-0.6m can get a higher segmentation accuracy.
- Sigma is the Gaussian smoothing factor (default value is "1"). The greater the value is, the smoother the results are. The degree of smoothness can affect the number of trees being segmented. In the case of under-segmentation, it is recommended to reduce this value (e.g. 0.5); and in the case of over-segmentation, it is recommended to increase the value (e.g. 1.5).
- Moreover, beside the algorithm parameters, the CHM segmentation result can also be largely influenced by tree density and tree species. If the algorithm does not work well in s certain study area, users can try to use other segmentation algorithms to get the best segmentation result.
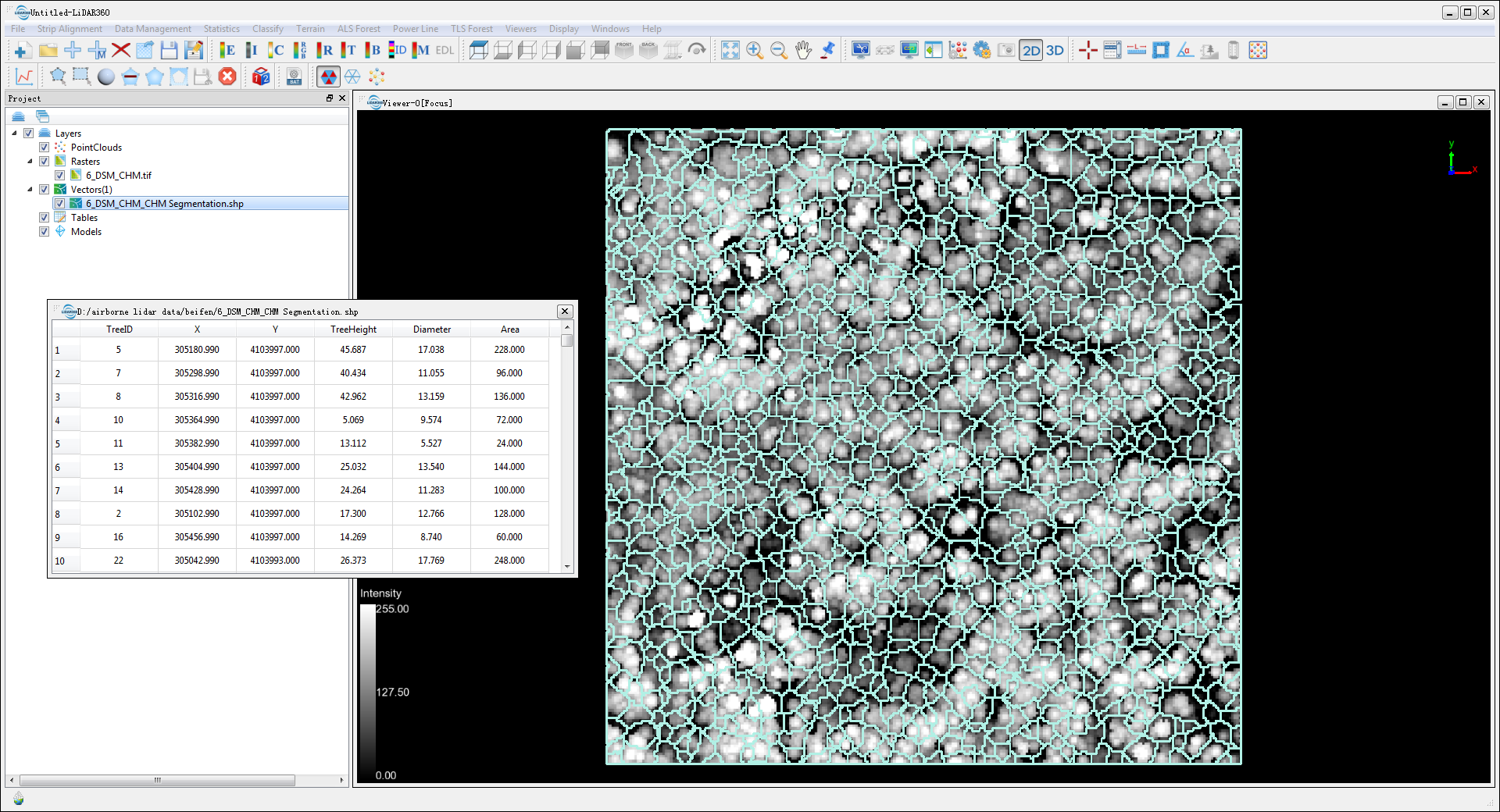
How to remove some results with small crown area after running CHM segmentation?
After running CHM segmentation, a shp file containing the tree boundary is obtained. The attribute table includes the ID, location, height, crown diameter and crown area of each tree. The data can be imported into a third-party software (e.g. ArcGIS), and you can remove the segmentation results with a small crown area according to the crown area attribute.
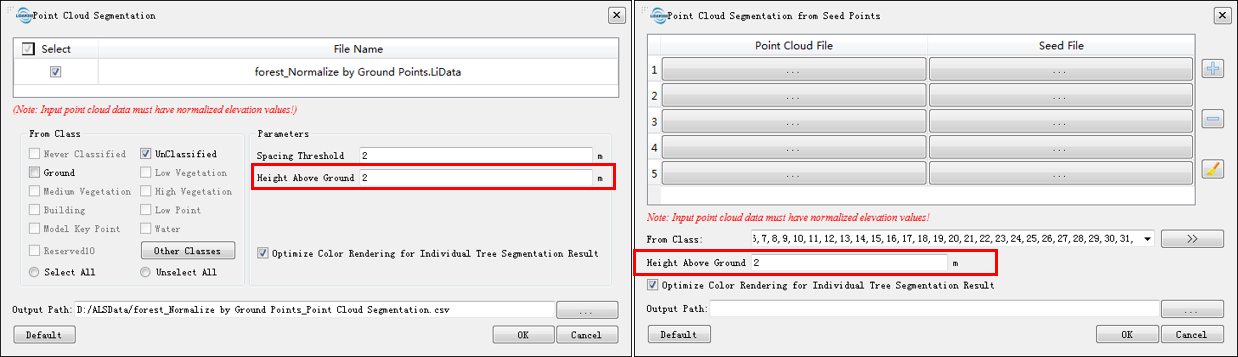
How to make point cloud data below 2m be participated in segmentation?
The parameter "Height Above Ground" on the Point Cloud Segmentation and Point Cloud Segmentation from Seed Points interfaces indicate that points below the value are not considered as part of the tree and will be ignored during the segmentation process. The default value is 2m. If you need to make the point cloud below 2m participate in the segmentation, the value can be reduced appropriately.
Which kind of segmentation method for coniferous and broad-leaved mixed forest data can be used to obtain higher accuracy?
- For coniferous and broad-leaved mixed forest data, CHM Segmentation is recommended.
The growth of trees in the area is not the same, how to achieve higher segmentation accuracy?
- It is recommended to clip the point cloud according to the growth as different data by Select Tools or Clip Tools and handle them separately.
If the tree canopy is covered in weeds, can tree identification still be performed in LiDAR360?
- Yes, it can.
How to export individual tree segmentation results to third-party software for analysis?
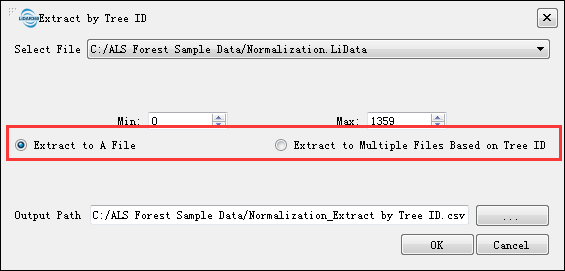
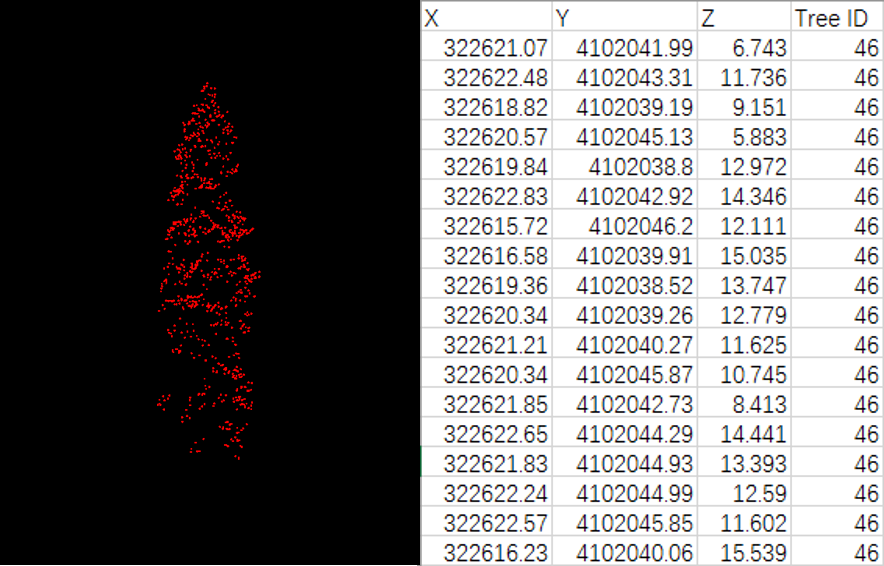
Click ALS Forest > Extract by Tree ID, the segmented point cloud can be exported to CSV file for subsequent analysis using other software. LiDAR360 supports exporting each tree as a separate CSV file or exporting all points as one file. The exported CSV file is shown in the figure below, which contains X, Y, Z coordinates and tree ID information.
How many sample data files are required for regression analysis?
- The number of sample data used for regression analysis is not clearly defined. In general, under the premise of ensuring the accuracy of plot location and measurement, the greater the number of sample data is, the higher the accuracy of regression analysis can achieve. Sample sites should be randomly selected and representative to cover different forest types within the study area. A sample size less than 30 is referred as a small sample, and a sample size of 30 or greater is referred as a large sample. To ensure regression analysis accuracy, the recommended sample size should be greater than or equal to 30 (you should also consider the size and complexity of the study area).
How to choose the independent variables involved in the regression analysis?
- The elevation percentiles obtained from LiDAR data are generally the independent variables for regression analysis. However, specific elevation percentiles are not all the same for different study areas.
Can trained regression models be used for other data?
Yes. Click ALS Forest > Regression Analysis > Run Existing Regression Model. Available regression models (Linear Regression, Support Vector Machine, Fast Artificial Neural Network and Random Forest Regression) can be used to estimate forest metrics.
Can I export the independent variables (e.g. elevation percentiles) generated by LiDAR360 into third-party software (e.g. SPSS, R) for regression analysis?
- Yes. Independent variables provided by LiDAR360 including Elevation Percentile, Elevation Density, Intensity Percentile, Leaf Area Index, Canopy Cover and Gap Fraction. Among them, Elevation Percentile, Elevation Density and Intensity Percentile are in CSV formats, and they can be imported into third-party software such as SPSS directly. Leaf Area Index, Canopy Cover, and Gap Fraction are in TIF formats that can be converted to text format by ArcGIS and imported into third-party software.
@inproceedings{
author={ Li W K, Guo Q H, Jakubowski M K and Kelly M},
title={A new method for segmentation individual trees from the LiDAR point cloud},
booktitle={ Photogrammetric Engineering and Remote Sensing,78(1):75-84},
year={2012}
}
What if the TLS Stem Extraction runs in a flash or there is no change in the classification result?
-The function of TLS Stem Extraction is based on deep learning and needs to use GPU. Make sure the latest driver has been installed on your computer.
-For Windows7 System, the driver need to be installed includes:
451.67-desktop-win8-win7-64-international-whql.exe
GeForce_Experience_v3.20.3.63.exe
Please select the appropriate driver according to your own operating system for your Nvidia GPU and installation.
If you still cannot run this function after installing the latest driver, please check whether the required system patches are installed. For example, Windows 7 needs to install the following patches:
Windows6.1-KB3068708-x64.msu
Windows6.1-KB3080148-x64.msu
Please make sure all the required patches are correctly installed on your computer.
After single tree classification, which column in the result table is the height of the tree? What if not?
- After single trees are divided, there is no tree elevation value in the result table, only X and Y coordinate values. To get the elevation attribute of each tree in the table, you can: first use the DEM tool to generate the DEM of the plot, and then use the "Foundation Forestry -> Tree Attribute -> Extended Single Tree Attribute" tool to make the DEM file according to the single tree attribute. The coordinate position of the tree divided by the wood, and the elevation value can be assigned to the CSV table.
Why is the tree flat when the scanned data is viewed in the cross-section? Is there any way to improve it (the scan is scanned according to the normal trajectory), in this case, it is easy to have problems fitting the DBH through the software?
- Considering the fact that the tree trunk is flat in the tree scan results, it may be because the sapling plants are relatively small. For large-scale woodland data, it is recommended that the scanning trajectory be more curved; during data calculation, in LiBackPack-BP In the software, first uncheck the smoothing option, and the data will not be smoothed.
There is a big difference between the results of single-tree segmentation and the actual number of single-trees. It is ruled out that the DBH fitting is inaccurate and non-parameter setting problems?
- Exclude the DBH fitting accuracy and parameter setting problems, then the cause of this problem may be the inconsistency between the original data unit and the LiDAR360 parameter setting unit. For example, the original data unit is feet, while the LiDAR360 data processing unit is unified as meters. Unit conversion is required before data processing.
- Conversion method: If the original data is in the las format, directly convert "las to LiData", and select "feet" as the source unit; if the original data format is LiData, first "convert to las" and then perform the above operations.
Why can't I generate seed points or perform CHM segmentation after the CHM file is generated normally?
- This problem is usually caused by poor CHM quality, which is difficult for the algorithm to identify, and is usually associated with poor DEM quality. You can generate TIN based on the point cloud according to the manual, edit TIN to ensure terrain quality, generate high-quality DEM based on TIN, and then generate seed points/segmentation for CHM.
Why is the number of trees in the segmentation result different from the number of seed points when segmenting individual trees based on seed points ? How to deal with this situation?
- The discrepancy between the number of trees in the segmentation result and the number of seed points is due to the competitive strategy used in point cloud segmentation. Trees with poor morphology may be incorrectly identified as other trees. To solve this, Import the CSV table and seed point table generated by single tree segmentation into the software at the same time. The position of a single tree and the position of the seed point are usually very close, forming a point pair. At this time, the isolated point is the seed point that has not formed a single tree. The single tree point cloud can be manually edited at this position to adjust the result.
Why is it that after generating a CHM file normally, seed points cannot be created / CHM segmentation cannot be performed?
- This issue is usually caused by poor CHM quality, which makes it difficult for the algorithm to recognize features, and is often associated with poor DEM quality. According to the manual, you can generate a TIN based on the point cloud, edit the TIN to ensure terrain quality, generate a high-quality DEM based on the TIN, and then create seed points/segmentation for the CHM.
Trunk Based Segmentation Failed? (Classify by Deep Learning Classification Failed?)
- This error is typically related to the GPU computing environment. To ensure stable operation of the deep learning model, we recommend the following:
Recommended solution: Update your graphics driver from the official NVIDIA website.
Alternative solution: Switch the computing device to "CPU" in the processing settings and try again (i.e., uncheck the "Prioritize GPU" option).