Classify Model Key Points
Brief
This function can thin a certain level of the classified points. It is generally used to generate a sparse point set that retains the key points in the complex terrain area and thin the points in the flat area from the extracted dense ground points.
The idea of the algorithm is: first, meshing of point cloud data, and then use the seed points in the grid to establish the initial triangulation network. According to the upper and lower boundary thresholds, the points that meet the conditions are added to the triangulation network. The process is iterated until all of the key points of terrain model are classified. In the following figure, the yellow point is the ground point and the purple point is the key point of terrain model.

Usage
Click Classify > Classify Model Key Points
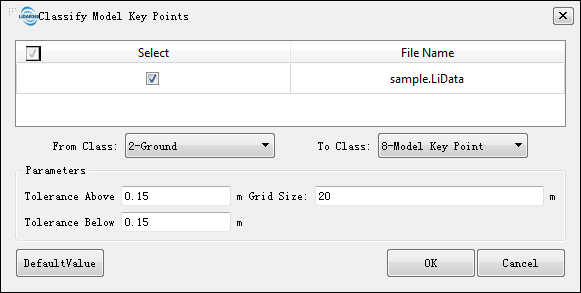
Settings
- Input Data: The input file can be a single point cloud data or a point cloud dataset, which must be opened in the LiPowerline software.
- From Class: Source class(es).
- To Class: Target class.
- Tolerance Above (m, default value is"0.15"): The maximum allowable elevation tolerance value over the triangulation model composed by the original points. The larger the value, the more sparse the key points will be extracted, and vice versa.
- Tolerance Below (m, default value is"0.15"): The maximum allowable elevation tolerance value under the triangulation model composed by the original points. The larger the value, the more sparse the key points will be extracted, and vice versa.
- Grid Size (m, default value is"20"): The value is used to ensure the density of key points extracted from the model. For example, if you want to ensure that there is at least one point in the grid every 20 meters, this value is set to 20.
- DefaultValue: Click this button to set all parameters as default.